Spring原理及应用
[TOC]
1.1 Spring特性
问:Spring有哪些特点?
轻量级、控制反转、面向切面、面向容器、灵活。
1 | graph TB |
- 轻量级
- 核心Jar包小
- 模块化,按需引入
- 控制反转
- 一个对象所依赖的其他对象会自动传递给它
- 实现对象依赖的解耦
- 面向切面
- 提高系统内聚性
- 抽取公共的业务,只需关注核心业务
- 面现容器
- 实现了对象配置化生成
- 实现了对象生命周期管理
- 框架灵活
- 对象可以声明式创建
补充:JavaBean
JavaBean是一种Java类,通过封装属性和方法成为具有某种功能,或者是处理某个业务的对象。必须有一个缺省的构造函数,每个属性都有get\set方法,可序列化。
1.2 Spring模块
Spring是模块化的,可以按需引入。

常用模块有:核心容器层Core Container,数据访问层Data Access,Web应用层Web Access。
1.2.1 核心容器层
主要有 Srping-Beans、Spring-Core、Spring-Context、SpEL等模块组成。
Spring-Beans *
基于 工厂模式 实现 对象的创建 。XML或者注解实现声明式的对象管理。
Spring-Core *
Spring核心功能实现,包括控制反转IOC和依赖注入DI。
控制反转模式/思想是通过依赖注入方法来实现的。在某个实例中引用另一个Bean实例的时候,Spring会自动将此实例传入。
Spring-Context
继承自Spring-Beans,实现国际化、上下文、事件传播、第三方库集成等等功能。
SpEL
Spring 表达式语言,Spring Expression Language。
用于在运行过程中查询和操作对象实例。
1.2.2 数据访问层

1. JDBC *
Spring持久化层基于JDBC抽象层实现了在不同数据库之间灵活切换,而不用担心不同数据库之间SQL语法的不兼容。
2.ORM *
对象\关系映射。
对象属性与关系型数据库中的字段进行映射。
ORM模块提供了对象关系映射API的集成,包括JPA(Java Persistence API)、JDO(Java DataObject)和Hibernate等。基于该模块,ORM框架能很容易地和Spring的其他功能(例如事务管理)整合。
3.OXM
OXM模块提供了对OXM实现的支持,比如JAXB、Castor、XML Beans、JiBX、XStream等。
4.JMS *
JMS模块包含消息的生产(Produce)和消费(Consume)功能。从Spring 4.1开始,Spring集成了Spring-Messaging模块,用于实现对消息队列的支持。
5. **事务处理 ***
Spring声明式事务只需要通过注解或配置即可实现事务的管理,具体的事务管理工作由Spring自动处理,应用程序不需要关心事务的提交(Commit)和回滚(Rollback)。
1.2.3 Web应用层
Web交互和数据传输功能。
主要包含Web、Web-MVC、Web-Socket、Web-Portlet。
Web *
Web应用基本功能,HTTP客户端及Spring远程调用中与Web相关的部分。
Web模块基于Servlet监听器初始化IoC容器。
Web-MVC *
Web-MVC模块为Web应用提供了MVC和REST API服务的实现。
Spring的MVC框架使数据模型和视图分离,数据模型负责数据的业务逻辑,视图负责数据的展示。
同时,Web-MVC可与Spring框架的其他模块方便地集成。
Web-Socket
Web-Socket模块提供了对WebSocket-Base的支持,用于实现在Web应用程序中服务端和客户端实时双向通信,尤其在实时消息推送中应用广泛。
Web-Portlet(没用过)
Web-Portlet模块提供了基于Portlet环境的MVC实现,并提供了与Spring Web-MVC模块相关的功能。
1.3核心Jar包
其实就是上面说的各种模块的Jar包。


1.4 Spring注解
1.4.1注解配置
SpringBoot自动配置,使用XML的就不看了
1.4.2 常用注解



整理一下自己常用的,或者说应该知道的
| 类别 | 注解 | 说明 |
|---|---|---|
| Bean声明 | @Component | 组件,没有明确定义的角色 |
| @Service | 服务 | |
| @Controller | 控制器 | |
| Bean注入 | @Autowired | 服务依赖注入 |
| 配置类注解 | @Configuration | 声明此类为配置类,包含Value属性可以直接指定属性值 |
| @Bean | 注解在方法上,声明该方法返回值注入容器中 | |
| @ComponentScan | 对组件进行扫描 | |
| AOP注解 | @Aspect | 声明一个切面,使用@After等注解定义通知,可将拦截规则(切点)作为参数 |
| @After | 在方法后执行 | |
| @Before | 在方法前执行 | |
| @Around | 在方法前和后执行 | |
| @PonitCut | 声明切点 | |
| SpringMVC注解 | @Controller | 控制器 |
| @RequestMapping | 映射Web请求的地址和参数,包括访问路径和参数 | |
| @ResponseBody | 可以返回JSON到前端 | |
| @RequestBody | 可以将Request参数放入Request Body体中 | |
| @RestController | @Controller和@ResponseBody的结合,可以返回消息的一个Controller | |
1.5 IOC原理
1.5.1 IOC简介
Spring通过一个配置文件描述Bean和Bean之间的依赖关系,利用Java的反射功能实例化Bean并建立Bean之间的依赖关系。
抽象工厂+反射。
先读取配置文件,后生成实例。
根据类名动态生成对象:f = (类名) class.forName(类名字符串).newInstance()
1.5.2 Bean装配流程
- 读取配置、注解信息
- 读取Bean配置信息:Spring在启动时会从XML配置文件或注解中读取应用程序提供的Bean配置信息
- 并在Spring容器中生成一份相应的Bean配置注册表;
- 然后根据这张注册表实例化Bean,装配好Bean之间的依赖关系,为上层业务提供基础的运行环境。
其中Bean缓存池为HashMap实现。Spring Bean的装配流程如图。


1.5.3 Bean作用域
五种作用域,分别为:
- Singleton,单例
- Prototype,原型
- Request,请求级别
- Session,会话级别
- Global Session,全局
作用域就是用来形容Bean容器中的一个Bean的作用范围。类似于public等修饰符。
1. Singleton
单例模式。IoC容器中,只会存在一个Bean对象,其他所有Bean引用的依赖都指向这一个Bean。
多线程下不安全。
Spring中默认的就是Singleton作用域。
2. Prototype
原型模式。
每次通过Bean容器获取一个Prototype的Bean时,都会创建一个新的实例,每个Bean实例都有自己的属性和状态。
3. Request
HTTP请求范围。
一次HTTP请求中是同一个Bean,而不同的HTTP请求则是不同的Bean。
当前请求结束后,这个Bean也会被销毁。
4. Session
一次HTTP Session中是同一个Bean,仅在当前Session中有效。
不共享数据,Session结束后销毁。
5. Global Session
全局的HTTP Session中返回同一个Bean。
尽在使用Porlet Context时有效。
通俗来讲,会话(Session) 是通信双方从开始通信到通信结束期间的一个上下文(Context)。这个上下文是一段位于服务器端的内存:记录了本次连接的客户端机器、通过哪个应用程序、哪个用户登录等信息.
连接(Connection):连接是从客户端到ORACLE实例的一条物理路径。连接可以在网络上建立,或者在本机通过IPC机制建立。通常会在客户端进程与一个专用服务器或一个调度器之间建立连接。
会话(Session) 是和连接(Connection)是同时建立的,两者是对同一件事情不同层次的描述。简单讲,连接(Connection)是物理上的客户端同服务器的通信链路,会话(Session)是逻辑上的用户同服务器的通信交互。
1.5.4 Bean生命周期

一文读懂 Spring Bean 的生命周期_riemann_的博客-CSDN博客
Bean 自身的方法
比如构造函数、getter/setter 以及 init-method 和 destory-method 所指定的方法等,也就对应着上文说的实例化 -> 属性赋值 -> 初始化 -> 销毁四个阶段。
容器级的方法(BeanPostProcessor 一系列接口)
主要是后处理器方法。比如 InstantiationAwareBeanPostProcessor、BeanPostProcessor 接口方法。这些接口的实现类是独立于 Bean 的,并且会注册到 Spring 容器中。在 Spring 容器创建任何 Bean 的时候,这些后处理器都会发生作用。Bean 级生命周期方法
可以理解为 Bean 类直接实现接口的方法,比如 BeanNameAware、BeanFactoryAware、ApplicationContextAware、InitializingBean、DisposableBean 等方法,这些方法只对当前 Bean 生效。三级方法是一级一级进行扩展的:
首先是最基本的Bean自身方法,进行最基本的创建:
之后是容器级处理方法,主要是后置处理方法,在各个阶段前后进行额外的处理:
最后是Bean级方法,只对当前Bean生效,进行额外属性的赋值:
日后需要去看看这个视频讲的不错:Spring之Bean的生命周期详解_哔哩哔哩_bilibili




1.5.5 四种依赖注入
这一块建议阅读Spring IoC有什么好处呢? - 知乎 (zhihu.com),可以弄清楚到底为啥要用这四种注入方法。
- 构造器注入
- set方法注入
- 静态工厂注入
- 实例工厂注入
1. 构造器注入
构造器注入指通过在类的构造函数中注入属性或对象来实现依赖注入。
构造方法传入参数:
1 | //在构造函数中注入message属性 |
xml配置文件:
1 | <!--定义Bean实例并在构造函数constructor-arg中注入message属性--> |
2. set方法注入
set方法注入是通过在类中实现get、set方法来实现属性或对象的依赖注入的。
1 | public class PersionDaoImpl(String message){ |
xml配置文件
1 | <!--定义Bean实例并通过property注入id为123的属性值--> |
3. 静态工厂注入
静态工厂注入是通过调用工厂类中定义的静态方法来获取需要的对象的。
为了让Spring管理所有对象,应用程序不能直接通过“工厂类.静态方法()”的方式获取对象,而需要通过Spring注入(XML配置)的方式获取。代码如下。
1 | //1.定义静态工厂 |
上述代码定义了一个DaoFactory工厂类和getStaticFactoryDaoImpl()静态工厂方法,该方法实例化并返回一个StaticFactoryDaoImpl实例;
同时定义了一个SpringAction类,并通过setStaticFactoryDao获取注入的FactoryDao。
具体的XML注入语法如下。
1 | <!--1.定义获取工厂对象的静态方法--> |
上述代码中,第一个bean用来获取工厂及工厂方法,第二个bean用来实际注入。
4. 实例工厂注入
实例工厂注入指的是获取对象实例的方法是非静态的,因此首先需要实例化一个工厂类对象,然后调用对象的实例化方法来实例化对象。具体代码如下。
1 | public class DaoFactory{ //1.实例工厂 |
1 | <bean name="springAction" class="SpringAction"> |
上述代码定义了一个name为factoryDao的工厂类,并通过factory-method定义了实例化对象的方法,这里实例化对象的方法是一个名为getFactoryDaoImpl的方法。该方法返回一个工厂类,在springAction中通过标签注入工厂实例。
1.5.6 自动装配的5种方式
- 手动装配
- 基于XML配置
- 基于注解
- 自动装配
- no:不启用自动装配,通过显式设置ref属性来进行对象装配。
- byName:通过参数名自动装配,Bean的autowire被设置为byName后,Spring容器试图匹配并装配与该Bean的属性具有相同名字的Bean。
- byType:通过参数类型自动装配,Bean的autowire被设置为byType后,Spring容器试图匹配并装配与该Bean的属性具有相同类型的Bean。
- constructor:通过设置构造器参数的方式来装配对象,如果没有匹配到带参数的构造器参数类型,则Spring会抛出异常。
- autodetect:首先尝试使用constructor来自动装配,如果无法完成自动装配,则使用byType方式进行装配。
1.6 Spring AOP原理
1.6.1 AOP简介
AOP,面向切面编程。将公共的与核心业务无关的部分提取出来,提高代码复用率,降低耦合度。
- 核心关注点:业务核心
- 横切关注点:公共部分,比如日志、事务、权限认证。

1.6.2 AOP核心概念
- 切面,Aspect:切面类,在这里面写抽取的额外公共逻辑。
- 连接点,JoinPoint:被拦截的方法,也就是原方法,需要在这前面或者后面执行公共逻辑。
- 切入点,Pointcut:切面中的某个方法,在这前面或者后面执行公共逻辑。@Pointcut注解写切点表达式后跟一个函数,代表原来的方法。
- 通知,Advice:也就是公共逻辑执行的位置,对应Before、After那几个注解。前置通知,后置通知,成功通知,异常通知,环绕通知五类。
- 目标对象:原来的对象,也就是代理的目标对象。
- 织入,weaving :将切面应用到目标对象并执行代理对象创建的过程。
这些观念可以结合下面的具体例子来看。
具体例子:Spring AOP SpringBoot集成 - 柠檬五个半 - 博客园 (cnblogs.com)
1.编写业务类:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
/**
* @desc: 核心业务模块
* @author: CSH
**/
public class AopController {
public void Curry(){ System.out.println("库里上场打球了!!"); }
public void Harden(){ System.out.println("哈登上场打球了!!"); }
public void Durant( int point){ System.out.println("杜兰特上场打球了!!"); }
}2.定义切面类:在类上添加@Aspect 和@Component 注解即可将一个类定义为切面类。
@Aspect注解 使之成为切面类@Component注解 把切面类加入到IOC容器中
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
/**
* @desc: 经纪人切面
* @author: CSH
**/
public class BrokerAspect {
/**
* 定义切入点,切入点为com.example.demo.aop.AopController中的所有函数
*通过@Pointcut注解声明频繁使用的切点表达式
*/
")
public void BrokerAspect(){}
/** * @description 在连接点执行之前执行的通知 */
@Before("BrokerAspect()")
public void doBeforeGame(){
System.out.println("经纪人正在处理球星赛前事务!");
}
/** * @description 在连接点执行之后执行的通知(返回通知和异常通知的异常) */
@After("BrokerAspect()")
public void doAfterGame(){ System.out.println("经纪人为球星表现疯狂鼓掌!"); }
/** * @description 在连接点执行之后执行的通知(返回通知) */
@AfterReturning("BrokerAspect()")
public void doAfterReturningGame(){ System.out.println("返回通知:经纪人为球星表现疯狂鼓掌!"); }
/** * @description 在连接点执行之后执行的通知(异常通知) */
@AfterThrowing("BrokerAspect()")
public void doAfterThrowingGame(){ System.out.println("异常通知:球迷要求退票!"); }
}
@Pointcut("execution(public * com.example.demo.aop.AopController.*(..)))"),AOP切点表达式,表示要在哪里切入(在这个方法前后执行切入的函数)- @Before(“BrokerAspect()”) :其中的函数名是
@Pointcut注解之中的,也就是切点之前执行。- @After:在连接点执行之后执行的通知(返回通知和异常通知的异常)
- @AfterReturning:在连接点执行之后执行的通知(返回通知)
- @AfterThrowing:在连接点执行之后执行的通知(异常通知)
可以看到,原业务类无任何更改,只是新写了这么一个Aspect类,就做到了在原方法之前或者之后执行额外方法。所以说做到了低耦合
最后,Around注解可以在方法前和后执行:
2
3
4
5
6
7
8
9
10
11
12
public void doAroundGame(ProceedingJoinPoint pjp) throws Throwable {
try{
System.out.println("经纪人正在处理球星赛前事务!");
pjp.proceed();
System.out.println("返回通知:经纪人为球星表现疯狂鼓掌!");
}
catch(Throwable e){
System.out.println("异常通知:球迷要求退票!");
}
}这里主要是
ProceedingJoinPoint pjp这个参数,表示切入点的方法。
pjp.proceed();就表示执行原方法,在这一行的前后进行切面逻辑的编写即可。以及,带参数的方法:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
/**
* @desc:技术统计
* @author: CSH
**/
public class GameDataAspect {
/**
* 定义切入点,切入点为com.example.demo.aop.AopController中的所有函数
*通过@Pointcut注解声明频繁使用的切点表达式
*/
")
public void GameDataAspect(int point){ }
/** * @description 使用环绕通知 */
@Around("GameDataAspect(point)")
public void doAroundGameData(ProceedingJoinPoint pjp,int point) throws Throwable {
try{
System.out.println("球星上场前热身!");
pjp.proceed();
System.out.println("球星本场得到" + point + "分" );
}
catch(Throwable e){
System.out.println("异常通知:球迷要求退票!");
}
}
}修改切点表达式,传入参数即可。


1.6.3 AOP代理的两种方式
两种方式:CGLib动态代理和JDK动态代理。
Spring默认的策略:
- 如果是目标类接口,使用JDK动态代理;
- 否则使用CGLib动态代理。
代理模式。
代理分为静态代理和动态代理:
- 静态代理:就是我们自己手写的,在编译前定义好代理类/接口。
- 动态代理:通过JDK反射机制在程序运行后创建
动态代理又分为JDK代理和CGLib代理:
- JDK动态代理:委托类(原来的目标类)必须实现接口,代理类和委托类实现同样的接口,然后代理类对其增强。
- CGLib动态代理:委托类不需要实现接口,而是代理类来继承委托类。
底层源码就先不深挖了。。。
JDK动态代理通过反射机制来实现,有一定的性能问题。
CGLib性能稍高,是通过一个叫FastClass的机制来实现的,简单来说就是对类中的方法进行一个索引。
CGLib不能代理 final 的方法\类,因为final修饰不能被继承/重写。
1.6.4 AOP的5种通知类型
也就是Advice,那几个位置。

1.6.5 AOP的代码实例
(上面已经举过例子了)
在Spring中,AOP的使用比较简单,如下代码通过@Aspect注解声明一个切面,通过@Pointcut定义需要拦截的方法,然后用@Before、@AfterReturning、@Around分别实现前置通知、后置通知和环绕通知要执行的方法。

1.7 Spring MVC原理
MVC,模型-视图-控制器。
围绕一个DispatcherServlet,分发请求。
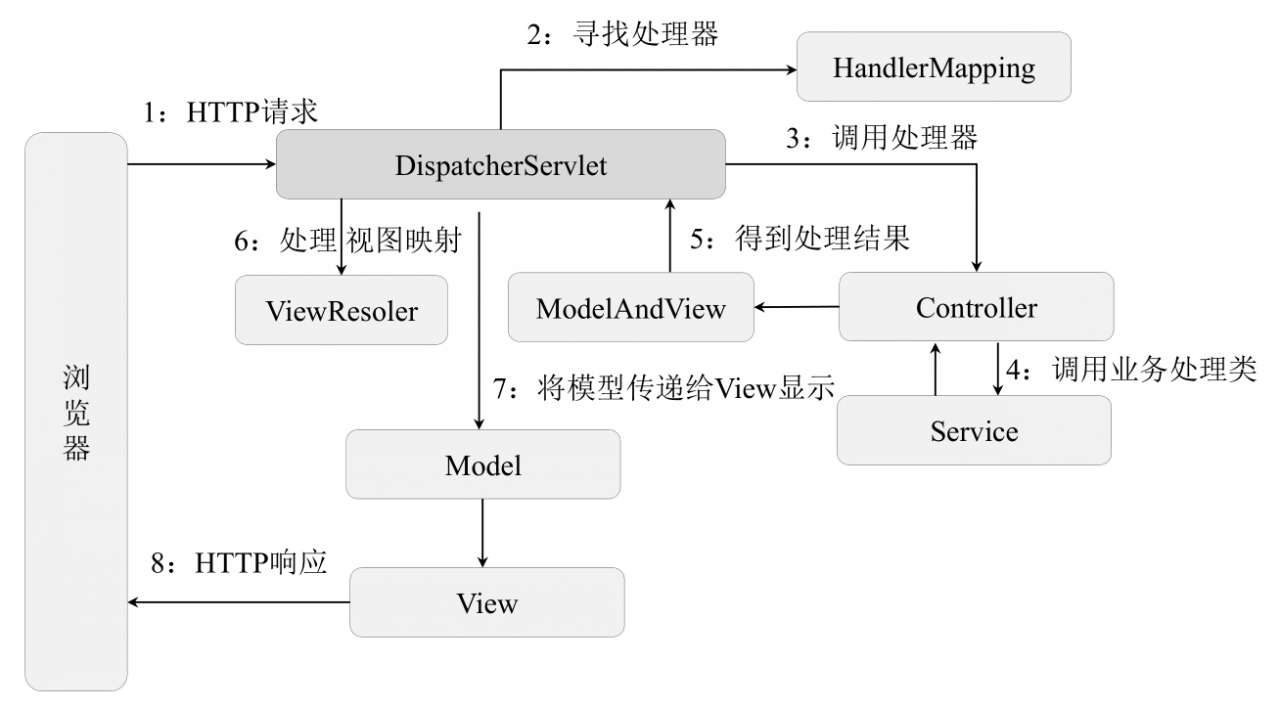
1.8 事务
事务的特性:ACID,原子性,一致性,隔离性,持久性。
1.8.1 本地事务
JDBC的本地事务:

1.8.2 分布式事务
跨数据库,分布式事务操作
- 跨数据库
- 同一类型数据库,多个数据源
- 不同数据库
Java事务编程接口JTA,和Java事务服务JTS,提供了分布式事务服务。
- 事务管理器:负责所有事务参与单元的协调与控制。
- XA协议的资源管理器:XA协议定义了事务管理器与资源管理器之间的接口;资源管理器负责不同数据库具体的事务执行操作。

1.8.3 两阶段提交协议
二阶段提交协议,Two-phase Commit,简写为2PC。一般也称为XA方案。
两阶段提交协议用于保证分布式事务的原子性。 即所有数据库,要么都执行要么都不执行。
两个阶段:1.准备阶段;2.提交阶段。

我们需要引入一个协调者来管理所有的节点,负责各个本地资源的提交和回滚,并确保这些节点正确提交操作结果,若提交失败则放弃事务。
这里事务管理器是指事务协调者,资源管理器是事务参与者。
准备阶段
为每个参与者都发送Prepare消息。
返回消息
返回失败(例如权限验证不通过)
返回成功:每个参与者在本地执行事务,写本地的undo和redo日志,但不提交,返回成功消息。
等所有参与者都返回结果之后,进入提交阶段。
提交阶段
- 所有的都OK了,那么就提交;
- 只要有一个不OK或者超时的,就给全部参与者发送回滚消息。
事务的执行和释放是在JPA中基于锁来实现控制的。
分布式事务理论-二阶段提交(Two-phase Commit) - 简书 (jianshu.com)
分布式一致性之两阶段提交协议、三阶提交协议 - 知乎 (zhihu.com)
同样还有改进的3PC,三阶段提交协议。
优缺点总结。
数据不一致问题:
- 只有一部分参与者接收到了提交请求并执行提交操作,但其他未接到提交请求的那部分参与者则无法执行事务提交。于是整个分布式系统便出现了数据不一致的问题。
- 协调者再发出DoCommit 消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。
同步阻塞问题:当本地资源管理器占有临界资源时,其他资源管理器如果要访问同一临界资源,会处于阻塞状态。



==严重依赖于数据库层面来搞定复杂的事务,效率很低,绝对不适合高并发的场景。==
在微服务中,一般来说某个系统内部如果出现跨多个库的这么一个操作,是不合规的。每个服务只能连自己的库。操作别人的库,必须通过别的服务来接口调用,不能直接操作。
1.9 Mybatis缓存
MyBatis缓存分为一级缓存和二级缓存。
一级缓存默认开启,而且是不能被关闭的。

1.9.1 一级缓存
缓存到SqlSession中。
缓存的数据结构是用的Map,key为MapperId + Offset + Limit + SQL +所有入参。
如果相同SQL的两次查询中间出现了Commit操作(增删改),则会清空SqlSession一级缓存,再重新查询进行缓存。

每个SqlSession中持有了Executor,每个Executor中有一个LocalCache。
一级缓存总结
- MyBatis一级缓存的生命周期和SqlSession一致。
- MyBatis一级缓存内部设计简单,只是一个没有容量限定的HashMap,在缓存的功能性上有所欠缺。
- MyBatis的一级缓存最大范围是SqlSession内部,有多个SqlSession或者分布式的环境下,数据库写操作会引起脏数据,建议设定缓存级别为Statement。
1.9.2 二级缓存
简单来说,二级缓存就是全局变量,一级缓存就是局部变量;不过这里是先全局后局部的。
二级缓存是可以跨SqlSession的,多个SqlSession共享一个缓存。
进入一级缓存的查询流程前,先在CachingExecutor进行二级缓存的查询

二级缓存总结
- MyBatis的二级缓存相对于一级缓存来说,实现了 **
SqlSession之间缓存数据的共享 **,同时粒度更加的细,能够到namespace级别,通过Cache接口实现类不同的组合,对Cache的可控性也更强。 - MyBatis在多表查询时,极大可能会出现脏数据,有设计上的缺陷,安全使用二级缓存的条件比较苛刻。
- 在分布式环境下,由于默认的MyBatis Cache实现都是基于本地的,分布式环境下必然会出现读取到脏数据,需要使用集中式缓存将MyBatis的Cache接口实现,有一定的开发成本,==直接使用Redis、Memcached等分布式缓存可能成本更低,安全性也更高。==



